
Real time Geometry Extraction and Vectorization of Objects from Point-Cloud Data (PART 2)
Date:
Tag: Semantic Surface Segmentation, 3D Point Cloud Processing, Lidar Data, Meshing
Venue: Imaging, Vision & Pattern Recognition Group (IVPR)
Collaboration: Department of Electronics and Telecommunication Engineering & Department of Computer Science and Engineering, Jadavpur University, Kolkata, India
Supervisor : Prof. Ananda Shankar Chowdhury, Prof. Sanjoy Kumar Saha
Timeline: July’ 17 - Dec’ 20
- Establishment of a pipeline for real time reconstruction of geometric objects from point cloud data. Fast surface segmentation, semantic labeling, and object grouping are the major constituting subjects of the pipeline
This is an extension of our previous work Real time Geometry Extraction and Vectorization of Objects from Point-Cloud Data (PART 1).
Single snapshot rotating LiDAR scan
 ”
”
(a) Synthetic scene with scanned point cloud overlayed (b) Point cloud with distance color coded from blue(least) to red(highest)
 ”
”
Process flow for the entire system, the first two stages can be made online if data is sampled from Lidar on the fly.
 ”
”
(a) A schematic showing the formation of point cloud by Lidar and (b) the resultant point cloud
For Mesh creation, Normal Estimation, Surface Segmentation please refer to our previous work: Real time Geometry Extraction and Vectorization of Objects from Point-Cloud Data (PART 1)
Surface feature extraction and classification:
- After formation of surface segments they are to be classified to assign a semantic label. A feature vector fl is formed for all unique labels l in L. For a cloud the list of such vectors is stored in the map F = {< fl, sl > ∀ unique l ∈ L} where sl is the semantic class corresponding to all points with label l. For classification, a number of classifiers have been tried as discussed below. During training sl is supplied to the classifier and during testing the classifier reports the sl for an fl. For all the segments the feature vectors are formed using Algorithm 3. The concatenated histogram of surface normals of a segment along with the surface density form the feature to represent the semantic. Each of the surface normal histograms hi, hj and hk is a distribution of the ˆi,ˆj and kˆ components respectively of all surface normals of a segment. The histograms are b-dimensional. For the present work, we have empirically set the value of b as 16 . Let x stands for a normal component . Then, the function B(x) as used in the algorithm determines the bin in the corresponding histogram hx. The present work is concerned with semantic differentiation between different types of surface namely “plane”,“ground plane”, “cylinder”, “sphere” and “cone”. If an environment can be defined as a composition of such basic generator surfaces then with supervised combination of surfaces, complex models can be estimated. Also surface like “ground plane” has immediate use in robot navigation. It can be observed from Algorithm 2 that the histograms are normalized individually. This is done in order to prevent bias towards a particular component as the surface is composed of normals with variances differing for the components. The density factor also helps to bias the classifier towards correcting the labels of bigger segment proposals. During training the label of a feature vector is chosen as the one corresponding to the majority of points in it. Due to local contextual surface propagation logic it may happen that different surfaces with a smooth transition may come under the same segment, the majority voting mitigates the effect of bad labeling in such cases. The proposed methodology uses a statistical approach to prepare surface segment proposals and subsequently use them for semantic label prediction using classical classifier i.e. feature is not learnt rather engineered. This provides an insight into the structural properties of point cloud from spinning Lidar. Though deep classifiers are becoming popular, point cloud segmentation using them are computationally very expensive and requires sophisticated hardware. The proposed approach on the other hand can work on low configuration hardware providing decent accuracy, without sacrificing much on speed.
 ”
”
“For a detailed look at the operation of Blensor tool check this link out”
Synthetic dataset:
- A synthetic dataset is created using the “Blensor” tool. Environmental model files were created that contained regular shaped objects in different orders of scale, orientation, density and occlusion. Four kinds of surfaces are placed on the scene, namely “plane”, “cylinder”, “sphere” and “cone”. The ground plane is labeled as a different surface namely “ground plane”. A Velodyne 32E Lidar was simulated with 0.2 degree horizontal resolution, thus producing a maximum possible point cloud of size 32×1800 for a scene. A Gaussian noise model with zero mean and variance of 0.01 is incorporated in the sensor. It must be admitted that in reality spinning Lidars are more accurate. However, here the extra noise is incorporated to test the robustness of the methodology. This is the primary dataset on which we have tested our surface segmentation process (i.e. prior to semantic label assignment). We refer to this as non semantic segmentation. At this stage only the surfaces are extracted. Figure 5 shows some sample scenes along with their point clouds. The different surfaces of “plane”, “ground plane”, “cylinder”, “sphere” and “cone” are colored as red, off white, blue, green and gray respectively. The color code holds for all other ground truths and semantic output. In order to put the semantic label, we rely on classifiers. Classifiers are to be trained with sufficient data. The data should correspond to a good mix of different types of surfaces. In our primary dataset 8 scenes have only one object and mostly contain ground planes. It may bias the training. Hence we have considered the remaining 24 scenes that are comparatively complex with multiple objects. Thus, corresponding clouds will have a good proportion of different types of surfaces. We need to augment the dataset also. For semantic labeling we consider this dataset and will refer to this one as semantic dataset.
 ”
”
Choice of classifier:
- For semantic classification of the extracted surfaces, traditional classifiers have been tried and their performances are evaluated. The table shows the comparative F1 score, precision and recall. As all the classifiers perform in the similar manner with respect to latency, accuracy became the important parameter in making the judgment. Even in terms of the accuracy parameters also all the classifiers provide reasonably good outcomes. It indicates the strength of the propose feature vector. Finally, based on the accuracy, we consider either of the top two classifiers i.e. random decision forest or extremely randomized tree can be selected for semantic labeling.
 ”
”
Comparison of performance: semantic segmentation:
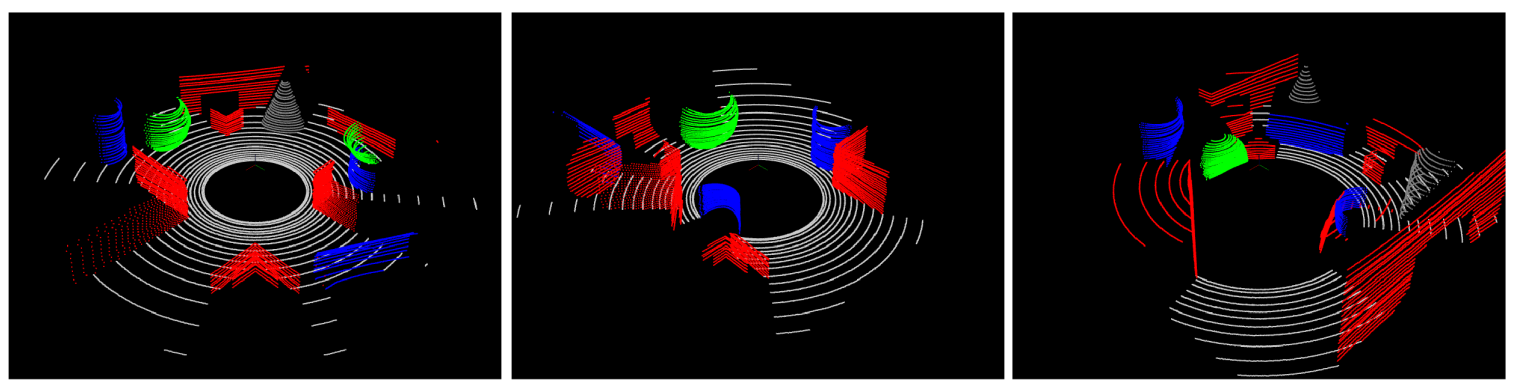
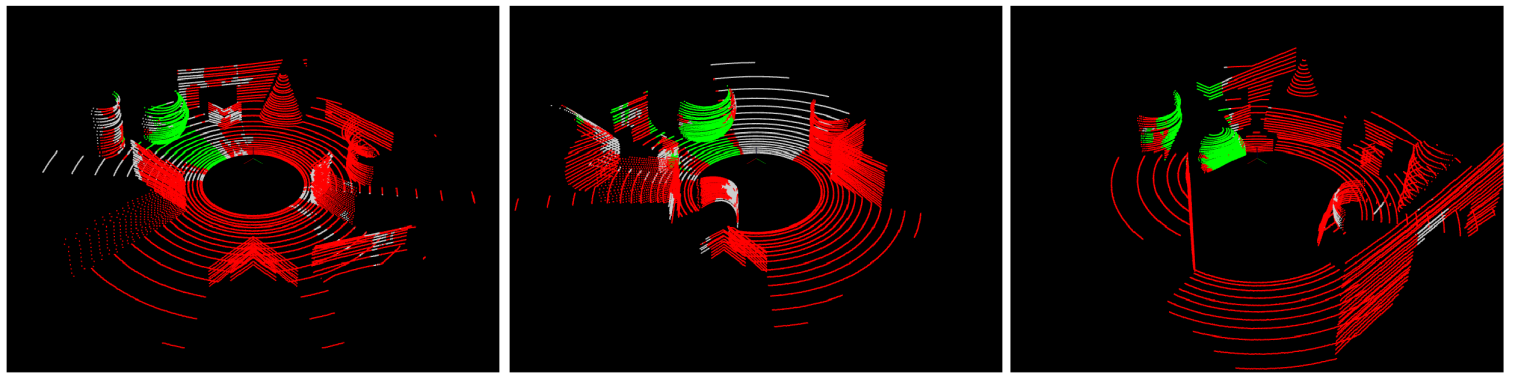
- For semantic segmentation the performance of the proposed methodology is compared with others using the mean intersection over union (MIoU) metric. As both ground truth and experimental output points belong to a definite semantic class, such a comparison is possible. Class Wise and overall comparison in terms of MIOU are made considering all the point clouds in the test set. Average precision, recall and F1 scores are also provided. The proposed methodology is compared with the pointnet and pointnet++ . These deep learning based methods are executed in a Linux machine with Intel Xeon 2.3GHz processor, Tesla K80 12GB GPU and 128GB DDR4 RAM. The pointnet and pointnet++ networks are designed to process small dense point clouds. On the other hand our dataset consists of large sparse clouds. Hence, contiguous points of size 1038 are fed to the network at one shot during both training and testing. This is due to the constraint posed by GPU memory. The method works with local contextual information and thus breaking the clouds into smaller chunks does not interfere with its working principle. Figure 7 shows the output of different methods corresponding to a few sample scenes. It can be observed that output of proposed methodology (for both the classifiers) is better than the others for all the classes. Although classes like “plane” and “ground plane” are well detected by the proposed methodology, detection of “cone” suffers. Table 4 shows the relative latency of the methods. Table 5 shows the relative accuracy of the methods in terms of average F1 score, precision and recall over all points in all clouds of the test set. Table 6 shows the class-wise and overall accuracy of the methods in terms of MIoU. For calculating the overall MIoU all points from all clouds are used rather than the average of MIoU for individual test clouds. From analysis of comparative results it can be said that the proposed methodology can deliver acceptable accuracy at real time speed. In general, spinning Lidars are operated at a maximum speed of 10 rotations per seconds and the average time of execution of our methodology is 115 to 124 milliseconds (8 to 8.7 FPS) depending on the choice of classifier. As a portion of the methodology is computed along with the Lidar spin, with a more optimized version the system can run in real time without any frame loss. Thus the proposed methodology can run on non-GPU low configuration system, in real time, delivering an MIoU accuracy of over 60%.
 ”
”
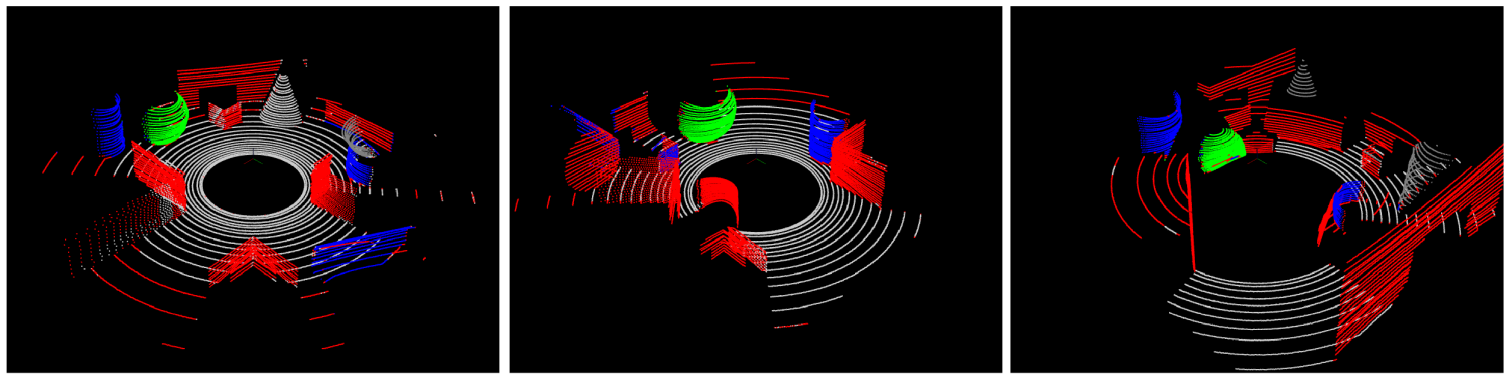
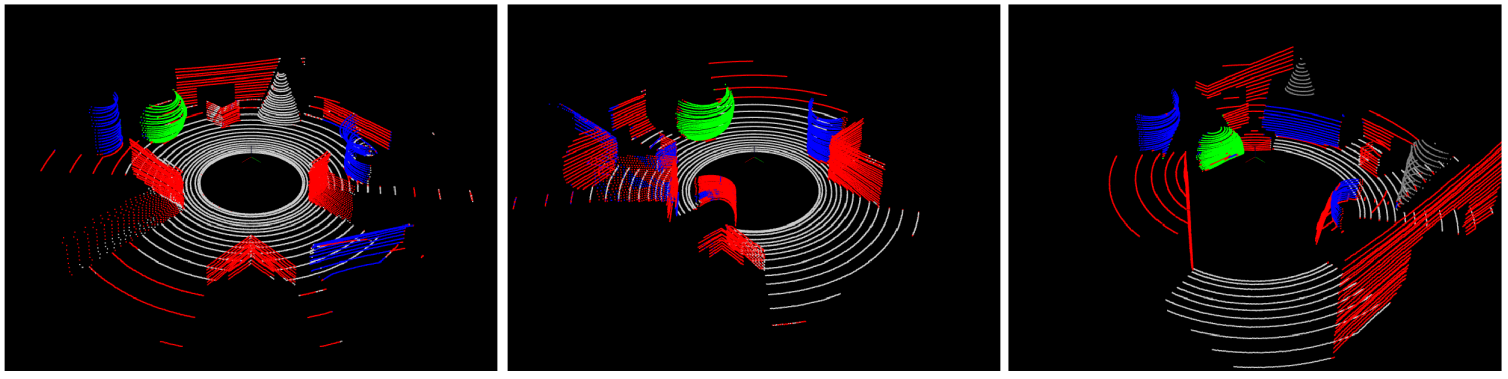
Comparison of output of different methods:
- From top to bottom rows correspond to ground truth of three scenes, output of pointnet, output of pointnet++, output of proposed methodology with RDF classifier, output of proposed methodology with ERT classifier respectively.
 ”
”
 ”
”
 ”
”
 ”
”
 ”
”
Conclusion
- The present work deals with the problem of semantic surface segmentation from Lidar point cloud data. The proposed methodology has a novel fast meshing process that generates surface mesh from the Lidar scan in an online fashion, facilitating fast computation of surface normals. Subsequently a statistical method generates segment proposals. The proposals are described with a novel feature vector based on the distribution of surface normals. Semantic labelling is done by feeding the feature vector as input to classifier. The performance of the proposed methodology is compared with some popular cloud segmentation methods. It is observed that the proposed methodology is significantly faster and provides higher classification accuracy. It can be concluded that the proposed methodology can deliver acceptable accuracy for robotic applications in real time and paves the way for further utilization of semantic surfaces towards generation of models and scene reconstruction.
More details about the work can be found on the following publication: Semantic Segmentation of Surface from Lidar Point Cloud